Data Privacy Measures
Administrative data are very likely to contain particularly sensitive information and therefore data privacy measures are critical prior to making sure that the privacy of individuals is protected. Minimizing the contact with individually identifiable and sensitive data may substantially reduce the vulnerability, inadvertent disclosure of, and targeted attacks on, administrative datasets. Strong privacy safeguards can be enablers in the use of administrative data for research and evidence-based policymaking.
Data Security and Data Privacy
Data security includes all measures, policies, and technologies put in place to protect data from external and internal threats. However, the application of data security measures alone does not always meet data protection requirements. Data protection still requires compliance with regulations regarding the collection, sharing, and use of the data an organization/ agency protects. Data security protects data from malicious threats while privacy is about the responsible management or use of that data.
When developing a data security policy, the focus of safeguarding measures is to prevent unauthorized access to data. When addressing data privacy issues, the focus is on the collection, processing, storage and transmission of data with the attention and consent of the parties involved. When an organization/agency collects data, individuals need to know what data is being collected, why it is needed, and with whom it is shared for transparency. Furthermore, the data subject must agree to these terms.
Data Privacy Laws and Regulations
Protecting privacy is critical while conducting any analysis or research with administrative data in an ethical way. Data systems must use rigorous system design to safeguard people's privacy and give them control over their data, in addition to responsive and adaptable architecture. A solid legal framework ought to complement these measures. The OECD's Fair Information Practices (FIPs) and emerging international good practices, such as the European Union's General Data Protection Regulation (GDPR), are two examples of global standards for data protection that should be followed when managing data used for identification and authentication.
The European Union’s (EU) 2016 General Data Protection Regulation (GDPR) is the most recent example of comprehensive regulation of data protection and privacy, setting a new threshold for international good practices. It has become an important reference point for global work in this area. The Article 5 of the GDPR , enshrines the core principles described above, requiring that personal data collection, storage, and use be:
→ processed lawfully, fairly and in a transparent manner in relation to the data subject;
→ collected for specified, explicit and legitimate purposes;
→ adequate, relevant and limited to what is necessary in relation to the purposes for which they are processed;
→ accurate and, where necessary, kept up to date;
→ kept in a form that permits identification of data subjects for no longer than is necessary for the purposes for which the personal data are processed; and
→ processed in a manner that ensures appropriate security of the personal data.
→ processed in a manner that ensures appropriate security of the personal data.
In addition to the above, implementing states are required to provide for a supervisory authority to monitor the application of the regulation (Article 51(1) of the GDPR).
In order to guarantee that privacy and data protection laws are adhered to, as well as the rights of individuals, personal identification systems and data protection are frequently subject to the supervision of an independent supervisory or regulatory authority. A single government official, an ombudsman, or a group with several internal and external members could serve as the supervisory authority. A key factor is the authority's true independence, which is measured by structural factors like the composition of the authority, the method of appointment of members, the authority's authority to exercise oversight functions, the allocation of sufficient resources, and the authority to make decisions that are meaningful without interference from outside parties.
Ensuring data privacy while accessing data
Data security includes all measures, policies, and technologies put in place to protect data from external and internal threats. However, the application of data security measures alone does not always meet data protection requirements. Data protection still requires compliance with regulations regarding the collection, sharing, and use of the data an organization/ agency protects. Data security protects data from malicious threats while privacy is about the responsible management or use of that data.
● Non-Aggregated & Personally Identifiable
This represents any data like health records, transport data, education where some uniquely identifiable personal information is present. This needs to be clearly set in a restrictive mode and access should be given only for authorized users within the government or agency
● Non-Aggregated & Personally Non-Identifiable
A personally identifiable record could be anonymized by removing personally identifiable fields. For example, health records could be anonymized and be given for research purposes. Educational data can help in identifying eligible students for disbursement of benefits like scholarships and create a database of employable resources.
● Aggregated, but personally identifiable
The sum-total of benefit disbursements or transactions such as aggregated electricity usage of a person. Even-though it is aggregated, these are personally identifiable. So, access should be given only for authorized users in the Government.
● Aggregated & Personally Non-Identifiable
These are typical datasets that can be published under OGD platforms like data.gov.in. In other words, this information can be petitioned and obtained under RTI. Such datasets are to be proactively released by every department under OGD initiative.
Setting-up data privacy measures to protect administrative data
Flowchart: Setting-up privacy measures for administrative data
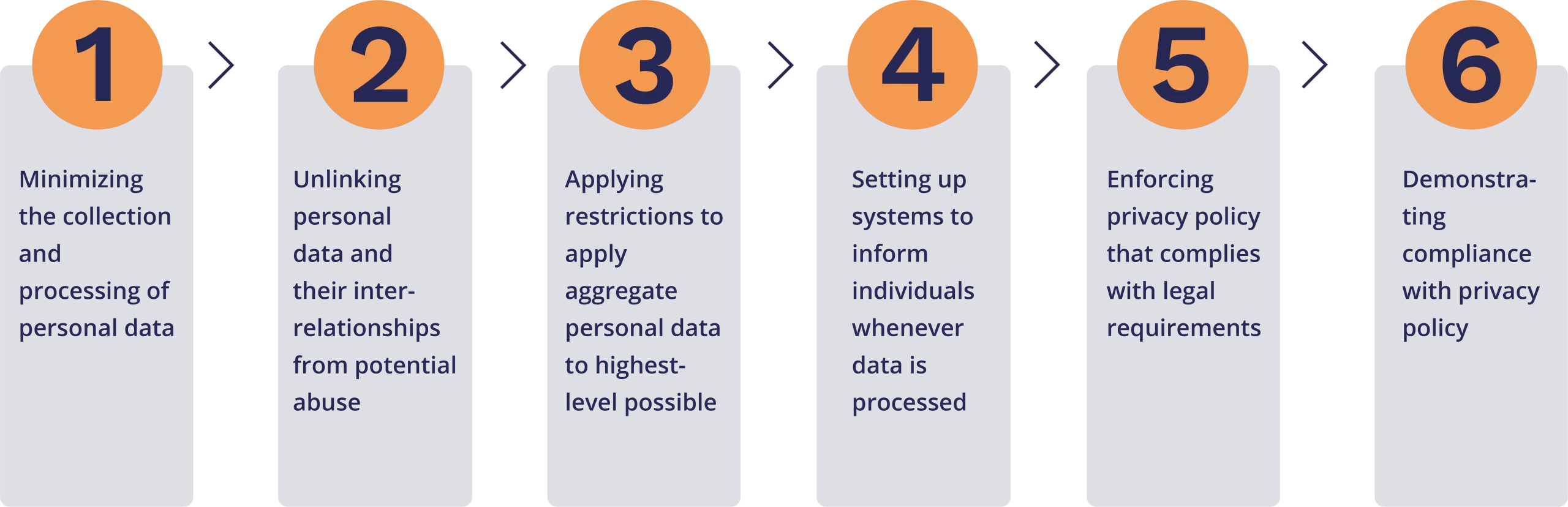
Step 1: Minimizing the collection and processing of personal data
To minimize the system's impact on privacy, reduce collecting personal data and processing to a minimum. Personal data should include only adequate, relevant, and limited to what is necessary for the purposes for which they are processed. Any specific points that a person brings to your attention, such as an objection, request for rectification of incomplete data, or request for the erasure of unnecessary data, should be taken into consideration. If personal data are not sufficient for the purpose for which they were collected, it should not be processed. In some cases, there may be a need to collect more personal information than originally planned to use in order to have enough for the purpose at hand. Hence, it must be checked on a regular basis to make sure that the personal data we have is still relevant and sufficient for the purposes, and we must get rid of any data no longer need. The majority of personal information should be deleted, and the agency should only keep the information necessary to create a basic record of a person they have removed from their search.
Unlinking personal data and their interrelationships from potential abuse
Hiding personal data and their interrelationships from plain view to achieve unlinkability and unobservability, minimizing potential abuse can be achieved by encryption, anonymization or use of pseudonyms. Anonymization and pseudonymization are methods that can be used to hide identities and personal data, but in distinct ways. "The processing of personal data in such a way that the data can no longer be attributed to a specific data subject without the use of additional information" is how the GDPR defines pseudonymization. As a result, personal and non-identifying data are exchanged, and additional information is required to recreate the original data. The term "anonymized data" refers to information that has been anonymized in such a way that no longer identifies the registered user. Here the connection between the individual and the data is completely severed. Separate, compartmentalize, or distribute the processing of personal data whenever possible to achieve purpose limitation and avoid the ability to make complete profiles of individuals.
Step 3:Applying restrictions to aggregate personal data to highest-level possible
Aggregate personal data to the highest-level possible when processing to restrict the amount of personal data that remains. Anonymize data using k-anonymity, differential privacy and other techniques (e.g., aggregate data over time, reduce the granularity of location data, etc.). “Differentially private methods provide strong promises to prevent outside parties from learning whether any individual is in the data, regardless of the background information available to others. In this it differs from traditional methods, which typically protect against specific, rather than general, methods of breaching privacy. Differentially private methods are being used more and more for releases of tabular data, for instance by the US Census Bureau (Machanavajjhala et al. 2008), Google (Erlingsson, Pihur, and Korolova 2014), Apple (Differential Privacy Team 2017), SafeGraph (SafeGraph 2020), but can also be challenging to implement[11].” [IDEA Handbook, Chapter 1] Differential privacy is a strict mathematical definition of privacy. At its simplest, imagine an algorithm that analyzes a dataset and computes its statistics (mean, variance, median, mode, etc.) of the data. Such an algorithm is said to be differentially private if it cannot be determined from the output whether personal data was included in the original record. In other words, the guarantees of the Differential Private Her algorithm are that its behavior hardly changes when one person joins or leaves the dataset. Anything an algorithm might output to a database that contains information about an individual is very likely to come from a database that has no information about that person. information. Best of all, this guarantee applies to everyone and all datasets. Differential privacy guarantees apply no matter how fancy your personal details are, or if your database contains other people's details. This formally ensures that no individual-level information about participants in the database has been compromised.
Step 4: Setting up systems to inform individuals whenever data is processed
Inform individuals when, for what purpose and by what means their data is being processed by sharing transaction or data breach notifications. A key principle of the by-design approach and international principles on privacy and data protection is to hold governments and third parties and their actors accountable for potential abuses. In addition, these standards should require general openness and transparency regarding policies and practices related to the management of personal information and should be readily available to individuals. One way of implementing personal oversight of data usage is by creating a platform or portal where individuals can log in to see their personal information and a record of who accessed the data, when and why. India also has a portal where a resident can view her record of authentication using her Aadhaar number. Such portals can be an important part of giving individuals control over their data. At the same time, platforms that require internet access may be exclusive to people in less-connected areas or those with low digital literacy. Practitioners therefore ensure that people have access to other procedures (such as physical offices) and grievance mechanisms to report and correct errors in data and to monitor who uses data and for what purposes.
Step 5: Enforcing privacy policy that complies with legal requirements
Enforce privacy policies that meet legal requirements through role-based access control and authorization. Authentication is the process of confirming that you are who you say you are. This involves matching an individual's claimed identity, verified by a credential (such as an ID card or a unique her ID number), against one or more of his authentication factors associated with that credential included. Secure authentication (that is, for higher security levels) requires a multi-factor approach. In general, any combination of authentication factors should include some or all of her three categories above. Additionally, sub-factors such as location (where you are) and time (when are you trying to authenticate) can be used in combination with other core factors to further condition authentication. Both online and offline authentication mechanisms share a common set of requirements to protect individuals claiming identity and to provide adequate security to consumers of identity (services, individuals, or dependents). In general, an authentication mechanism following legal requirements should do the following:
- • A known and easily accessible exception handling and complaint resolution protocol in case of authentication mechanism failure (e.g. false negative biometric results). No right, benefit, or entitlement may be denied (or made difficult to access) due to a failure of the identity system.
- • Eliminate opportunities for identity authorities or other actors to use transaction metadata to track or profile identity owners (e.g., by encryption, hashing, anonymizing data, decentralizing such data, etc.). Mandated by relevant laws and regulations, certain relationships between identity systems and relying parties are governed by legal agreements (eg, memorandum of understanding) that set out their respective responsibilities.
- • Determines the attributes, if any, that will be passed from the identity provider to the relying party/service her provider upon successful authentication of the user.
- • Establish a secure communication channel between the relying party and her identity provider to enable authentication workflows between the service provider and her identity provider applications. Manage digital identities including expiration, revocation, and renewal.
Step 6: Demonstrating compliance with privacy policy
Demonstrate compliance with privacy policies and applicable legal requirements using tamper-resistant logs and audits. To ensure that only authorized users have access to personal data for their authorized purposes, you need a way to track transactions and identify who accessed the data and when. Automatic tamper-proof logging of transactions involving identity data is a best practice method for organizational and personal oversight of how that data is used. Any log or audit data collected must comply with the data protection requirements of the identity system in question. The log should contain at least the following:[12]
- • protected from unauthorized access (and have that use monitored);
- • protected from unauthorized copying or exfiltration; and
- • devoid of personal data.
For example, in India and Estonia, logs are digitally signed to detect tampering. Additionally, Estonia has digitally signed logs that are concatenated, making it difficult to change history. New technologies such as blockchain could potentially make these protocols more secure, even against the authorities that control them, by making them immutable. Ensure logs are removed from application servers as soon as possible and sent to a central log management system. Whenever possible, send log data directly to a centralized log management system. Ensure log files and log transactions are encrypted in transit and at rest. Analyze log file activity to identify gaps in logging or corruption patterns that may highlight suspicious activity.
- ● What is the distinction between data security and data privacy?
- ● Protecting privacy is critical to conducting analysis and research with administrative data in an ethical way
- ● Give an overview of different relevant data privacy laws (GDPR etc)
- ● I think a checklist based on existing J-PAL project best practices for data privacy could be useful… ie what is PII? How can indirect identifiers be risky? What are the minimum must dos and best practices to be followed? [some of this is already covered below and looks great]
- ● Introduce new methods such as differential privacy (see IDEA Handbook chapter on Differential Privacy for reference, and privacy is also discussed with examples in the Handbook intro (quote pasted below)
“Differentially private methods provide strong promises to prevent outside parties from learning whether any individual is in the data, regardless of the background information available to others. In this it differs from traditional methods, which typically protect against specific, rather than general, methods of breaching privacy. Differentially private methods are being used more and more for releases of tabular data, for instance by the US Census Bureau (Machanavajjhala et al. 2008), Google (Erlingsson, Pihur, and Korolova 2014), Apple (Differential Privacy Team 2017), SafeGraph (SafeGraph 2020), but can also be challenging to implement. Chapter 6 provides an overview and details on the advantages and challenges of implementing differential privacy.”
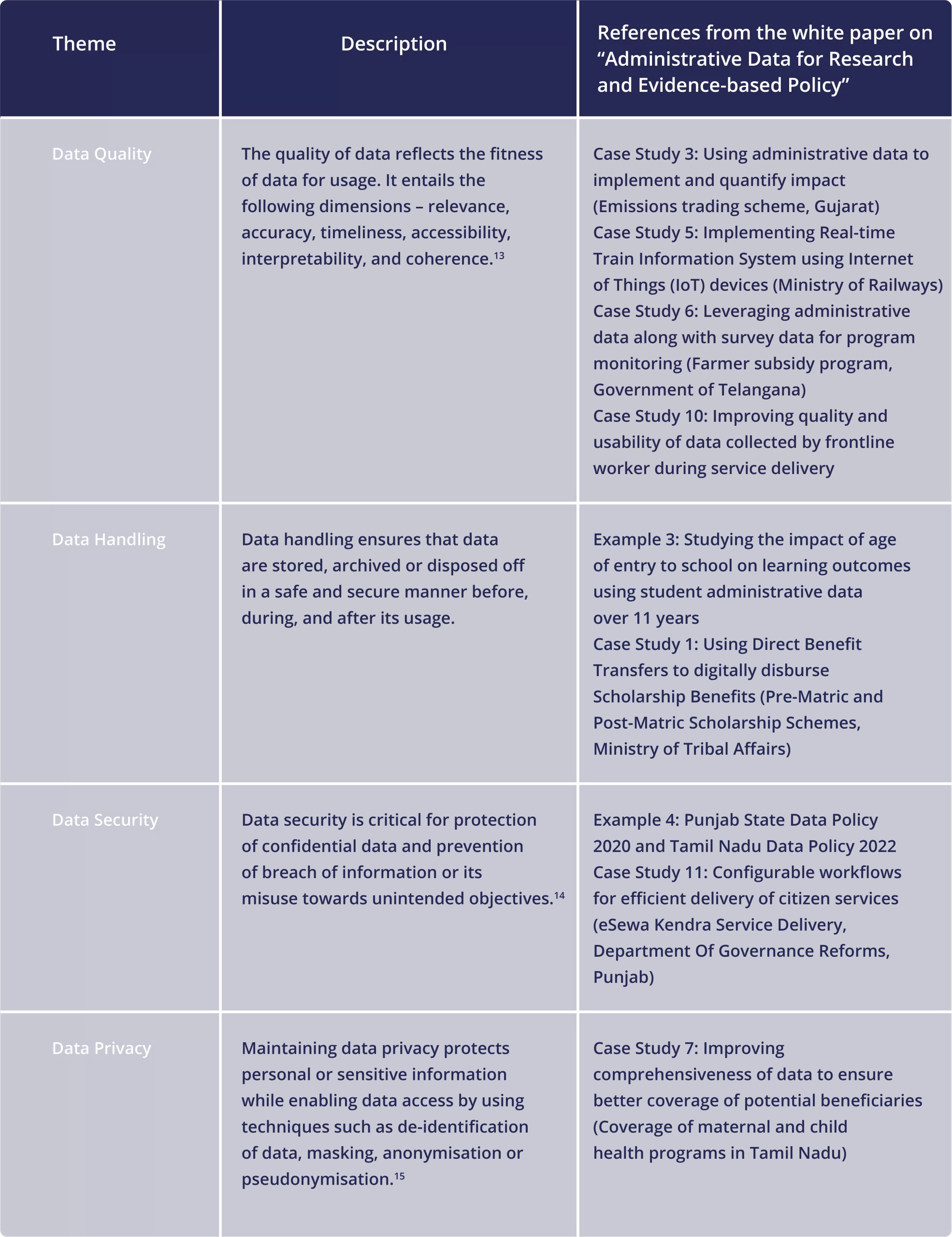
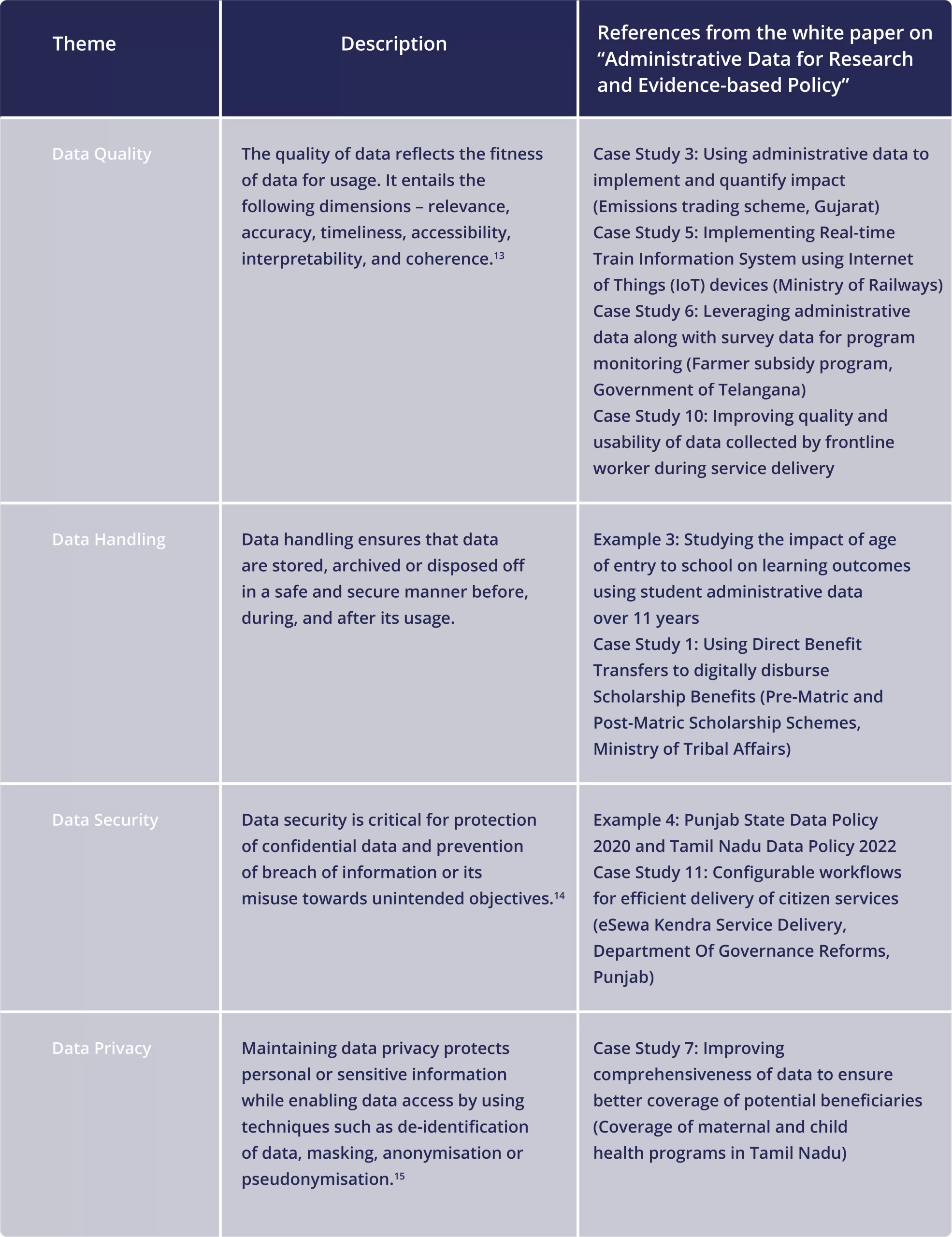
References from the white paper on “Administrative Data for Research and Evidence-based Policy”
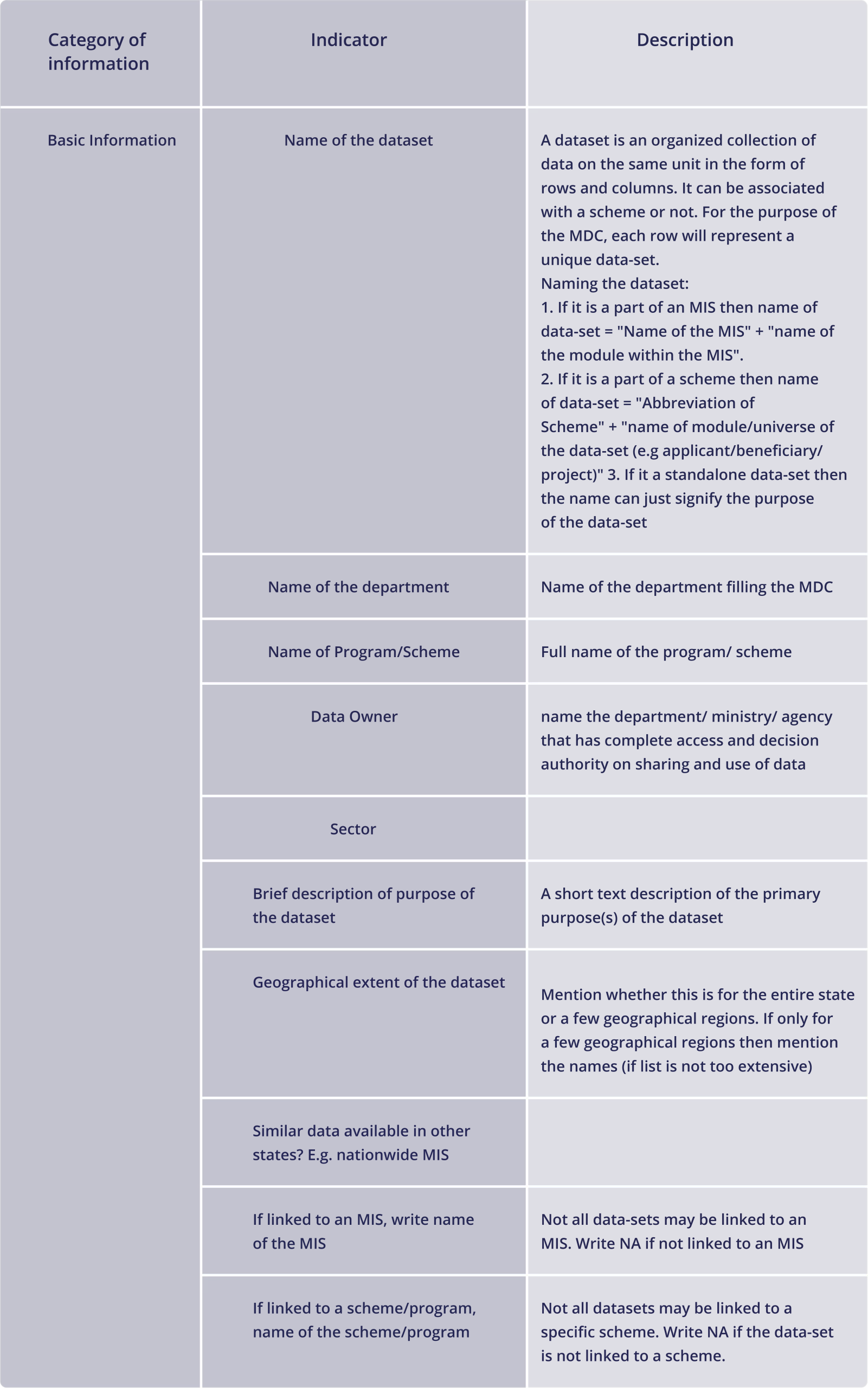
Sample Data Catalog Template
Sample Data Catalog Template






Footnotes
12Identification for Development (ID4D) Initiative: Guide to Privacy & Security
13Source: https://unstats.un.org/unsd/dnss/docViewer.aspx?docID=194#start
14 Reference: https://www.povertyactionlab.org/resource/data-security-procedures- Researchers
15Reference: https://unsdg.un.org/sites/default/files/UNDG_BigData_final_web.pdf
Additional Resources
- https://www.povertyactionlab.org/resource/data-security-procedures-researchers
- https://id4d.worldbank.org/guide/data-protection-and-privacy-laws
- High-Profile Policy-Relevant Research Powered by Administrative Data - J-PAL NA
- Why use administrative data? - J-PAL NA
- Using Administrative Data for Research and Evidence-Based Policy: An Introduction - IDEA Handbook
- Use of Administrative Records in Evidence-Based Policymaking - Groves, 2018
- Use of administrative data and social statistics - European Statistical System
- https://www.povertyactionlab.org/resource/data-quality-checks
- https://www.povertyactionlab.org/resource/using-administrative-data-randomized-evaluations
- Balancing privacy and data usability - IDEA Handbook
- Designing access with differential privacy - IDEA Handbook